Voy a poner bastantes servidores en producción, y la verdad no sé qué opción elegir.
Gentoo con firewalls openbsd
Debian con firewalls openbsd
Gentoo con gentoo
Debian con debian.
Tengo que ver documentación por ahí y a ver qué ponemos.
En principio me gusta la idea de Gentoo con OpenBSD, pero bueno habrá que buscar comparativas.
24 febrero 2005
21 febrero 2005
Cómo saber qué versión de glibc tenemos instalada
Siempre se me olvida la lbrería que me indica qué versión de glibc tengo.
Con ejecutar "/lib/libc.so.6" como usuario sin privilegios nos va a indicar qué versión de glibc tenemos en el sistema.
En mi caso la salida sería así:
jose@trinity jose $ "/lib/libc.so.6"
GNU C Library 20040808 release version 2.3.4, by Roland McGrath et al.
Copyright (C) 2004 Free Software Foundation, Inc.
This is free software; see the source for copying conditions.
There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE.
Compiled by GNU CC version 3.3.4 20040623 (Gentoo Linux 3.3.4-r1, ssp-3.3.2-2, pie-8.7.6).
Compiled on a Linux 2.4.21 system on 2004-10-24.
Available extensions:
GNU libio by Per Bothner
crypt add-on version 2.1 by Michael Glad and others
linuxthreads-0.10 by Xavier Leroy
BIND-8.2.3-T5B
libthread_db work sponsored by Alpha Processor Inc
NIS(YP)/NIS+ NSS modules 0.19 by Thorsten Kukuk
Thread-local storage support included.
For bug reporting instructions, please see:
.
Con ejecutar "/lib/libc.so.6" como usuario sin privilegios nos va a indicar qué versión de glibc tenemos en el sistema.
En mi caso la salida sería así:
jose@trinity jose $ "/lib/libc.so.6"
GNU C Library 20040808 release version 2.3.4, by Roland McGrath et al.
Copyright (C) 2004 Free Software Foundation, Inc.
This is free software; see the source for copying conditions.
There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE.
Compiled by GNU CC version 3.3.4 20040623 (Gentoo Linux 3.3.4-r1, ssp-3.3.2-2, pie-8.7.6).
Compiled on a Linux 2.4.21 system on 2004-10-24.
Available extensions:
GNU libio by Per Bothner
crypt add-on version 2.1 by Michael Glad and others
linuxthreads-0.10 by Xavier Leroy
BIND-8.2.3-T5B
libthread_db work sponsored by Alpha Processor Inc
NIS(YP)/NIS+ NSS modules 0.19 by Thorsten Kukuk
Thread-local storage support included.
For bug reporting instructions, please see:
18 febrero 2005
Más comandos
Ojeando un manual de shell avanzado, he encontrado una lista de comandos muy chula. La mayoría son conocidos, otros no me aparecían en el sistema, hasta que caí en la cuenta de que hay que instalarlos, que no vienen por defecto en bash.
Seguiré con estos repaso de comandos, lo mismo, cuando lo tenga completito, lo hago en una sóla página, pero los siguientes que encontré son un pelín más complicados de comprobar, puesto que son de terminales, con lo cual, hasta que no los pruebe no los publico
- users -> muestra el usuario actual
- groups -> muestra el grupo al que pertenece el usuario actual
- useradd -> para añadir usuarios, como root
- userdel -> para borrar usuarios, como root
- usermod -> para modificar una cuenta de usuario
- groupmod -> para modificar un grupo
- id -> muestra el uid y el gid del usuario
- who -> muestra todos los usuarios logeados en el sistema
- w -> muestra los usuarios logeados en el sistema y sus procesos asociados
- logname -> muestra el nombre de usuario actual, tal y como se encuentra en /var/run/utmp
- su -> para cambiar de usuario
- sudo -> para ejecutar cosas como otro usuarios. Previamente hay que modificar el archivo sudoers
- passwd -> para cambiar de contraseña
- last -> últimos usuarios logeados tal y como aparecen en /var/log/wtmp
- newgrp -> permite cambiar el grupo del usuario sin desconecta
- ac -> teóricamente para mostrar el tiempo conectado de los usuarios, pero yo no lo tengo instalado en el sistema ni posibilidad de instalación.
Seguiré con estos repaso de comandos, lo mismo, cuando lo tenga completito, lo hago en una sóla página, pero los siguientes que encontré son un pelín más complicados de comprobar, puesto que son de terminales, con lo cual, hasta que no los pruebe no los publico
17 febrero 2005
Aplicaciones para gestión de archivos
Hay dos aplicaciones muy interesantes que no se me tienen que pasar para trabajar con archivos.
Una es alien. Se trata de una herramienta para utilizar paquetes construidos para otras distribuciones; no está claro, es que me explico como el cu...., mejor pongo un ejemplo.
Supongamos que estoy utilizando Ubuntu; por supuesto los paquetes que instalaré para no complicarme la vida serán paquetes debian, .deb. Encuentro un paquete de una superaplicación que quiero instalar, pero mediante las fuentes es muy engorroso, y no tengo paquete "deb", sólo un "rpm", qué hacer?.
Lo primero es tener instalado "rpm". Una vez instalado utilizo el programa alien para transformarlo de "rpm" a "deb" con este comando:
Mola a que si, eh??.
Por supuesto tiene mogollón de opciones porque además se puede utilizar con paquetes de solaris, slackware, redhat, deb....
La otra aplicación chula es checkinstall.
Vamos a poner el tópico que pone todo el mundo. ¿Cuántas veces has necesitado un programa y no había ni rpm ni deb y sólo disponías de las fuentes? , instalarlo es fácil, pero a la hora de desinstalar, si no has apuntado todos los archivos que te añade al sistema, o los que te modifica, se hace una
labor tediosa, bueno salvo raras excpciones, que tienen desinstalador en las fuentes.
Bueno pues checkinstall en resumidas cuentas es un programa para instalar programas desde el código fuente, y poder desinstalarlos. En mi portátil no hay problema porque utilizo Gentoo, pero para otros como en la oficina que tengo Ubuntu, o en nuestros servidores que tenemos redhat, pues es muy útil.
Próximamente traduciré un artículo para linuxfocus, cuando lo tenga ya lo postearé aquí.
Una es alien. Se trata de una herramienta para utilizar paquetes construidos para otras distribuciones; no está claro, es que me explico como el cu...., mejor pongo un ejemplo.
Supongamos que estoy utilizando Ubuntu; por supuesto los paquetes que instalaré para no complicarme la vida serán paquetes debian, .deb. Encuentro un paquete de una superaplicación que quiero instalar, pero mediante las fuentes es muy engorroso, y no tengo paquete "deb", sólo un "rpm", qué hacer?.
Lo primero es tener instalado "rpm". Una vez instalado utilizo el programa alien para transformarlo de "rpm" a "deb" con este comando:
/usr/bin/alien --to--deb --keep--versionY voila, me va a aparecer el paquete .deb.
xbill_2.0--14_i386.rpm
Mola a que si, eh??.
Por supuesto tiene mogollón de opciones porque además se puede utilizar con paquetes de solaris, slackware, redhat, deb....
La otra aplicación chula es checkinstall.
Vamos a poner el tópico que pone todo el mundo. ¿Cuántas veces has necesitado un programa y no había ni rpm ni deb y sólo disponías de las fuentes? , instalarlo es fácil, pero a la hora de desinstalar, si no has apuntado todos los archivos que te añade al sistema, o los que te modifica, se hace una
labor tediosa, bueno salvo raras excpciones, que tienen desinstalador en las fuentes.
Bueno pues checkinstall en resumidas cuentas es un programa para instalar programas desde el código fuente, y poder desinstalarlos. En mi portátil no hay problema porque utilizo Gentoo, pero para otros como en la oficina que tengo Ubuntu, o en nuestros servidores que tenemos redhat, pues es muy útil.
Próximamente traduciré un artículo para linuxfocus, cuando lo tenga ya lo postearé aquí.
16 febrero 2005
Megabits
Una definición muy chula que he encontrado en Wikipedia para recordar siempre la diferencia entre Megabits y Megabytes:
Megabit
De Wikipedia, la enciclopedia libre.
El Megabit (Mbit o Mb) es una unidad de medida de información muy utilizada en las transmisiones de datos de forma telemática. Representa un millón de bits (1.000.000) y con frecuencia se le confunde con el Megabyte que equivale a 220 (1 048 576) bytes.
Cuando se expresa una velocidad de, por ejemplo, 2 Mbits/s se quiere decir que en un segundo se transmiten 2 millones de bits, o lo que es lo mismo, 2.000.000 / 8 = 250.000 bytes.
Cuestiones de contraseña
No sé qué paranoia ha entrado en todos los blogs últimamente con el cambio de contraseñas. Hay una cosa de la que soy partícipe. O se deniega el acceso externo, o se cambia la contraseña por defecto, y si no, pues ya dependes de la buena fe del que encuentre que tienes la contraseña por defecto.
Un enlace muy interesante que he encontrado viendo Kriptopolis ha sido éste:
Un enlace muy interesante que he encontrado viendo Kriptopolis ha sido éste:
http://www.cirt.net/
Se trata de una página en la que se recopilan contraseñas por defecto de diversos dispositivos y marcas. Muy útil cuando hay que resetear algún router y no se sabe la contraseña por defecto
Se trata de una página en la que se recopilan contraseñas por defecto de diversos dispositivos y marcas. Muy útil cuando hay que resetear algún router y no se sabe la contraseña por defecto
15 febrero 2005
Un pequeño repaso a los comandos
Simplemente quiero hacer un pequeño listado de comandos que seguramente iré ampliando, porque siempre aparecen comandos que se me olvidan, o que no conocía y que merece la pena conocerlos:
Lo dicho, se irá completando esta lista a medida que surgen comandos, o que los recuerdo, porque según lo estaba haciendo recordaba más :-)
- ls -> lista archivos, funciones bastantes complejas como listados recursivos (mirar manual).
- cat y tac -> concatenadores, tac es el reverso de cat. Pone al revés el archivo entero.
- rev -> pone al revés cada línea, es decir cada línea mantiene su orden en el archivo, pero el texto está al revés.
- cp -> copiar
- mv -> cortar, mover
- rm -> borrar
- rmdir -> borrar directorio
- chmod -> cambiar atributos de un archivo
- chown -> cambiar propietario de un archivo
- chgrp -> cambiar grupo de un archivo
- chattr -> cambiar atributos de un archivo, pero sólo para sistemas de archivo ext2 (o ext3, claro).
- ln -> crea enlaces blandos o duros a a archivos.
- basename -> muestra nombre eliminando cualquier elemento del directorio que lo precede, si se especifica también se elimina el sufijo final.
- find -> búsquedas, ni hablar de su tremenda utilidad
- xargs -> ejecuciones, también muy, muy útil.
- grep -> búsquedas de cadenas en archivos.
- sort -> ordena líneas.
- uniq -> muestra líneas no repetidas.
- expr -> para realizar operaciones matemáticas.
Lo dicho, se irá completando esta lista a medida que surgen comandos, o que los recuerdo, porque según lo estaba haciendo recordaba más :-)
14 febrero 2005
A vueltas con los gráficos
Volviendo a los problemillas con el rrdtool, ya tengo los gráficos principales que quiero controlar, y estos son, red (eth0 y eth1), carga de procesador, y memoria (ram y swap), para hacer honor a la verdad, me falta el número de conexiones, que haré luego en un momento.
Todas estas estadísticas las tengo de los cuatro servidores web. Obviamente tendría que hacer estadísticas totales sumando los valores, y del resto de servidores. La cuestión es que no sé qué más valores extraer, valores que no necesiten de leer ningún log, que simplemente los adquiera mediante snmp.
También tengo que valorar si realizar una aplicación o no, o modificar los archivos existentes, hay que valorarlo, teninedo en cuenta que próximamente voy a tener que monitorizar del orden de 14 máquinas.
Lo estudiaré y estudiaré la posibilidad de realizar la aplicación
Todas estas estadísticas las tengo de los cuatro servidores web. Obviamente tendría que hacer estadísticas totales sumando los valores, y del resto de servidores. La cuestión es que no sé qué más valores extraer, valores que no necesiten de leer ningún log, que simplemente los adquiera mediante snmp.
También tengo que valorar si realizar una aplicación o no, o modificar los archivos existentes, hay que valorarlo, teninedo en cuenta que próximamente voy a tener que monitorizar del orden de 14 máquinas.
Lo estudiaré y estudiaré la posibilidad de realizar la aplicación
Código da Vinci
Llevo escasamente una semana leyendo el Código da Vinci de Dan Brown. Previsiblemente lo voy a terminar hoy a la vuelta del trabajo.
Estoy totalmente enganchado con el contenido del libro, pero más que su contenido filosófico, su estilo de aventuras a lo Indiana Jones. Es bastante sencillo de leer, pero engancha. Pero en los últimos capítulos he leido unas cosas bastante interesantes. Además de las implicaciones del Opus, el Sangreal, bla, bla, bla.... los protagonistas "buenos y malos" me recuerdan a los hackers (en el sentido de investigadores, no de crackers), y el desarrollo último, por lo menos en los últimos capítulos, me recuerda a la defensa de Alan Cox de que todo el código debe ser compartido y accesible por todo el mundo. En definitiva, el fin último del GNU. Lo cual también me da pensar otras cosas. Así como en el libro la persona que defiende todos estos fundamentos utiliza artimañas nada lícitas, ¿son lícitos todos los medios que utiliza el software libre?, bueno el software libre no utiliza medios, la pregunta mejor formulada sería: ¿son lícitos todos los medios que utilizan los defendores del software libre?, o bien, ¿tendría que ser todo un "dejar hacer"?.
Sé que no es una inquietud fundamental para el discurrir de los acontecimientos del software libre, pero bueno, es una duda que a veces me asalta a veces.
Estoy totalmente enganchado con el contenido del libro, pero más que su contenido filosófico, su estilo de aventuras a lo Indiana Jones. Es bastante sencillo de leer, pero engancha. Pero en los últimos capítulos he leido unas cosas bastante interesantes. Además de las implicaciones del Opus, el Sangreal, bla, bla, bla.... los protagonistas "buenos y malos" me recuerdan a los hackers (en el sentido de investigadores, no de crackers), y el desarrollo último, por lo menos en los últimos capítulos, me recuerda a la defensa de Alan Cox de que todo el código debe ser compartido y accesible por todo el mundo. En definitiva, el fin último del GNU. Lo cual también me da pensar otras cosas. Así como en el libro la persona que defiende todos estos fundamentos utiliza artimañas nada lícitas, ¿son lícitos todos los medios que utiliza el software libre?, bueno el software libre no utiliza medios, la pregunta mejor formulada sería: ¿son lícitos todos los medios que utilizan los defendores del software libre?, o bien, ¿tendría que ser todo un "dejar hacer"?.
Sé que no es una inquietud fundamental para el discurrir de los acontecimientos del software libre, pero bueno, es una duda que a veces me asalta a veces.
10 febrero 2005
Cambio de nombre
Pues si, éste me gusta más, porque sí, porque soy un friki, y por cambiar un poco, que soy demasiado soso poniendo nombres.
09 febrero 2005
Autoalbum
Pues nada, que ahora tocaba hacer el autoalbum de las imágenes para ver los consumos. Lo primero que pensé fue en utilizar una clase en python, un autogenerador en php, un no sé cuánto en C. Ayer leyendo el Código Davinci me di cuenta de que con hacerlo en bash iba a tener lo que necesitaba.
Pues me puse manos a la obra, y pum!, he escrito un script muy pequeño, muy pequeño que me hace los enlaces de las imágenes de cada directorio. De momento no hace nada más, pero es que lo primero que tengo que hacer es tener gráficas de las máquinas, y luego ya veremos cómo las hacemos bonitas.
Total que el resultado provisional es este:

lo que de momento es una cagada, porque parece que tiene ram libre, cuando no es así, y además no existe ram negativo :-(
Por cierto el código de mi minialbum es éste:
#!/usr/local/bin/bash
cd /usr/local/www/data-dist/rrd/imagenes/
for i in `ls -R|grep "./"|cut -c 3-|awk -F : '{print $1}'`;do
cd $i
ls *.png
if [ $? -eq 0 ];then
rm -rf index.html
touch index.html
for l in `ls *.png`;do
nombre=`basename $l .png`
echo " $nombre" >> index.html
$nombre" >> index.html
done
fi
cd /usr/local/www/data-dist/rrd/imagenes/
done
Por cierto, el enlace a bash es de freebsd, ya se sabe, úsese #!/bin/bash en linux :-)
Sé que no es un prodigio de la programación, pero cumple su función que es lo que importa :-)
Pues me puse manos a la obra, y pum!, he escrito un script muy pequeño, muy pequeño que me hace los enlaces de las imágenes de cada directorio. De momento no hace nada más, pero es que lo primero que tengo que hacer es tener gráficas de las máquinas, y luego ya veremos cómo las hacemos bonitas.
Total que el resultado provisional es este:
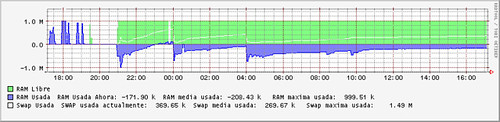
lo que de momento es una cagada, porque parece que tiene ram libre, cuando no es así, y además no existe ram negativo :-(
Por cierto el código de mi minialbum es éste:
#!/usr/local/bin/bash
cd /usr/local/www/data-dist/rrd/imagenes/
for i in `ls -R|grep "./"|cut -c 3-|awk -F : '{print $1}'`;do
cd $i
ls *.png
if [ $? -eq 0 ];then
rm -rf index.html
touch index.html
for l in `ls *.png`;do
nombre=`basename $l .png`
echo "
done
fi
cd /usr/local/www/data-dist/rrd/imagenes/
done
Por cierto, el enlace a bash es de freebsd, ya se sabe, úsese #!/bin/bash en linux :-)
Sé que no es un prodigio de la programación, pero cumple su función que es lo que importa :-)
08 febrero 2005
Creando gráficos con rrdtool
Bueno, ya tengo datos de memoria, y de carga de cpu. He creado el script "gráficos.sh" en el que con funciones y a base de repeticiones deposito los gráficos en un directorio, para luego verlos desde una página web mediante snmp:
#!/bin/bash
AHORA=`date +%s`
HACE_UN_DIA=$(($AHORA-86400))
HACE_DOS_DIAS=$(($AHORA-172800))
HACE_UNA_SEMANA=$(($AHORA-604800))
HACE_UN_MES=$(($AHORA-2419200))
HACE_UN_ANO=$(($AHORA-29030400))
dibuja_grafico()
{
/usr/local/bin/rrdtool graph /usr/local/www/data-dist/rrd/imagenes/servidor1/$1 -s $2 -e $3 -a PNG -b 1024 --width=700 DEF:ramt=/usr/local/www/data-dist/rrd/db/memoria1.rrd:ramtotal:MAX DEF:ramu=/usr/local/www/data-dist/rrd/db/memoria1.rrd:ramusada:MAX DEF:swu=/usr/local/www/data-dist/rrd/db/memoria1.rrd:swapusada:MAX AREA:ramt#80ff80:"RAM Libre\n" AREA:ramu#8080ff:"RAM Usada" GPRINT:ramu:LAST:"RAM Usada Ahora\:%8.2lf %s" GPRINT:ramu:AVERAGE:"RAM media usada\:%8.2lf %s " GPRINT:ramu:MAX:"RAM maxima usada\:%8.2lf %s\n" LINE1:swu#ffffff:"Swap Usada" GPRINT:swu:LAST:"SWAP usada actualmente\:%8.2lf %s" GPRINT:swu:AVERAGE:"Swap media usada\:%8.2lf %s " GPRINT:swu:MAX:"Swap maxima usada\:%8.2lf %s\n" LINE1:ramu#0000ff
}
dibuja_grafico 'memoriaa_ultimo_dia.png' $HACE_UN_DIA $AHORA
dibuja_grafico 'memoriab_dos_dias.png' $HACE_DOS_DIAS $AHORA
dibuja_grafico 'memoriac_ultima_semana.png' $HACE_UNA_SEMANA $AHORA
dibuja_grafico 'memoriad_ultimo_mes.png' $HACE_UN_MES $AHORA
dibuja_grafico 'memoriae_ultimo_ano.png' $HACE_UN_ANO $AHORA
El truquito de las letras detrás de la palabra memoria, es simplemente porque si hago un autoindex (que pretendía hacerlo en python) conseguimos que siga el orden de menos a más tiempo
Hay un pequeño fallo todavía, y son las unidades que salen en la gráfica. No se refiere a bytes, sino a miles por eso es un poco extraño, cuando encuentre la corrección debería ponerla aquí.
#!/bin/bash
AHORA=`date +%s`
HACE_UN_DIA=$(($AHORA-86400))
HACE_DOS_DIAS=$(($AHORA-172800))
HACE_UNA_SEMANA=$(($AHORA-604800))
HACE_UN_MES=$(($AHORA-2419200))
HACE_UN_ANO=$(($AHORA-29030400))
dibuja_grafico()
{
/usr/local/bin/rrdtool graph /usr/local/www/data-dist/rrd/imagenes/servidor1/$1 -s $2 -e $3 -a PNG -b 1024 --width=700 DEF:ramt=/usr/local/www/data-dist/rrd/db/memoria1.rrd:ramtotal:MAX DEF:ramu=/usr/local/www/data-dist/rrd/db/memoria1.rrd:ramusada:MAX DEF:swu=/usr/local/www/data-dist/rrd/db/memoria1.rrd:swapusada:MAX AREA:ramt#80ff80:"RAM Libre\n" AREA:ramu#8080ff:"RAM Usada" GPRINT:ramu:LAST:"RAM Usada Ahora\:%8.2lf %s" GPRINT:ramu:AVERAGE:"RAM media usada\:%8.2lf %s " GPRINT:ramu:MAX:"RAM maxima usada\:%8.2lf %s\n" LINE1:swu#ffffff:"Swap Usada" GPRINT:swu:LAST:"SWAP usada actualmente\:%8.2lf %s" GPRINT:swu:AVERAGE:"Swap media usada\:%8.2lf %s " GPRINT:swu:MAX:"Swap maxima usada\:%8.2lf %s\n" LINE1:ramu#0000ff
}
dibuja_grafico 'memoriaa_ultimo_dia.png' $HACE_UN_DIA $AHORA
dibuja_grafico 'memoriab_dos_dias.png' $HACE_DOS_DIAS $AHORA
dibuja_grafico 'memoriac_ultima_semana.png' $HACE_UNA_SEMANA $AHORA
dibuja_grafico 'memoriad_ultimo_mes.png' $HACE_UN_MES $AHORA
dibuja_grafico 'memoriae_ultimo_ano.png' $HACE_UN_ANO $AHORA
El truquito de las letras detrás de la palabra memoria, es simplemente porque si hago un autoindex (que pretendía hacerlo en python) conseguimos que siga el orden de menos a más tiempo
Hay un pequeño fallo todavía, y son las unidades que salen en la gráfica. No se refiere a bytes, sino a miles por eso es un poco extraño, cuando encuentre la corrección debería ponerla aquí.
Utilizando el rrdtool
Bueno el día no ha empezado demasiado bien, debido a que llegamos a la oficina y no había calefacción, y......, bueno, con la temperatura que hay ahora en Madrid como que no hay quién se quite la chaqueta en la oficina....
Bueno pues hoy he comenzado a instalar...otra vez... el "rrdtool" en un equipo con freebsd. Realmente instalar rrdtool es una tontería, lo que lleva más trabajo es preparar los scripts para la recopilación de datos, pero pensándolo bien, pues puedo hacer hasta una recopilación del estado de la impresora, aunque lo que estoy haciendo es para monitorizar unas máquinas que tenemos en Inglaterra.
Lo mismo que con sed, no quiero olvidarme de lo que estoy haciendo, así que voy a copiar extractos de los archivos que he creado hasta el momento.
Como decía la instalación en freebsd es bastante fácil, parecido a gentoo, simplemente me he ido al "port" de rrdtool y he tecleado "make install", me ha dado un error por culpa de unos parches, pero los he borrado y he vuelto a teclear "make install" y sin problema, se ha compilado e instalado.
De momento sólo estoy recopilando datos de la memoria ram y swap de 4 servidores, y todavía no he creado los scripts de generación de gráficos.
El archivo de creación de las bases de datos tenía algo escrito como esto, pero cuatro veces:
No escribo todos porque es una tontería, todos los mismos datos, pero distinta base de datos. Sé que podía hacer un superscript y automatizar, con bucles, y loops, y patatín y patatán..., bueno he hecho "copiar-pegar" que es una de las grandes novedades de la informática, y he cambiado los nombres de las bases de datos, así que no me ha llevado más de 30 segundos la creación de las bases, además si ha ido bien las de memoria ya no se vuelven a crear.
Hay dos archivos para recopilación de datos:
WEB1=213................ (como que voy a poner la de verdad ;-)
RECOP1="snmpget -v 1 -c public 213............."
TOTALSWAP=" .1.3.6.1.4.1.2021.4.3.0"
SWAPLIBRE=" .1.3.6.1.4.1.2021.4.4.0"
TOTALRAM=" .1.3.6.1.4.1.2021.4.5.0"
RAMLIBRE=" .1.3.6.1.4.1.2021.4.11.0"
En recopmemoria.sh tenemos un script como este (por supuesto con otros datos):
totalswap1=`$RECOP1$TOTALSWAP |awk '{print $4}'`
swaplibre1=`$RECOP1$SWAPLIBRE |awk '{print $4}'`
swapusado1=`expr $totalswap1 - $swaplibre1`
totalram1=`$RECOP1$TOTALRAM |awk '{print $4}'`
ramlibre1=`$RECOP1$RAMLIBRE |awk '{print $4}'`
ramusado1=`expr $totalram1 - $ramlibre1`
/usr/local/bin/rrdtool update /usr/local/www/data-dist/rrd/db/memoria1.rrd \ N:$totalram1:$ramusado1:$totalswap1:$swapusado1
Bueno y luego simplemente añadí una entrada en el cron que lo ejecute cada
5 minutos
*/5 * * * * /home/scripts/recopmemoria.sh >/dev/null 2>&1
Nota: he tenido que modificar al principo del recopmemoria.sh porque sino me daba un error al no encontrar la fuente del archivo de datos, de modo que he escrito:
#!/usr/local/bin/bash
cd /home/scripts
. datos-comunes
Por qué utilizo rrdtool?, pues por lo mismo que utilizo gentoo, por comodidad, sé que podría tener gráficas con mrtg, pero de hecho no tengo la flexibilidad que tengo con rrdtool, ni podría incluir más de dos fuentes de datos en una gráfica....y porque me da la gana, que yo no obligo a nadie a que ponga las gráficas que uso yo :-)
En siguientes entregas iré completando, a ver si puedo hacer un complemento majo para rrdtool.
Bueno pues hoy he comenzado a instalar...otra vez... el "rrdtool" en un equipo con freebsd. Realmente instalar rrdtool es una tontería, lo que lleva más trabajo es preparar los scripts para la recopilación de datos, pero pensándolo bien, pues puedo hacer hasta una recopilación del estado de la impresora, aunque lo que estoy haciendo es para monitorizar unas máquinas que tenemos en Inglaterra.
Lo mismo que con sed, no quiero olvidarme de lo que estoy haciendo, así que voy a copiar extractos de los archivos que he creado hasta el momento.
Como decía la instalación en freebsd es bastante fácil, parecido a gentoo, simplemente me he ido al "port" de rrdtool y he tecleado "make install", me ha dado un error por culpa de unos parches, pero los he borrado y he vuelto a teclear "make install" y sin problema, se ha compilado e instalado.
De momento sólo estoy recopilando datos de la memoria ram y swap de 4 servidores, y todavía no he creado los scripts de generación de gráficos.
El archivo de creación de las bases de datos tenía algo escrito como esto, pero cuatro veces:
/usr/local/bin/rrdtool create /usr/local/www/data-dist/rrd/db/memoria1.rrd \
DS:ramtotal:GAUGE:600:U:U \
DS:ramusada:GAUGE:600:U:U \
DS:swaptotal:GAUGE:600:U:U \
DS:swapusada:GAUGE:600:U:U \
RRA:AVERAGE:0.5:1:600 \
RRA:AVERAGE:0.5:6:700 \
RRA:AVERAGE:0.5:24:775 \
RRA:AVERAGE:0.5:288:797 \
RRA:MAX:0.5:1:600 \
RRA:MAX:0.5:6:700 \
RRA:MAX:0.5:24:775 \
RRA:MAX:0.5:288:797
DS:ramtotal:GAUGE:600:U:U \
DS:ramusada:GAUGE:600:U:U \
DS:swaptotal:GAUGE:600:U:U \
DS:swapusada:GAUGE:600:U:U \
RRA:AVERAGE:0.5:1:600 \
RRA:AVERAGE:0.5:6:700 \
RRA:AVERAGE:0.5:24:775 \
RRA:AVERAGE:0.5:288:797 \
RRA:MAX:0.5:1:600 \
RRA:MAX:0.5:6:700 \
RRA:MAX:0.5:24:775 \
RRA:MAX:0.5:288:797
No escribo todos porque es una tontería, todos los mismos datos, pero distinta base de datos. Sé que podía hacer un superscript y automatizar, con bucles, y loops, y patatín y patatán..., bueno he hecho "copiar-pegar" que es una de las grandes novedades de la informática, y he cambiado los nombres de las bases de datos, así que no me ha llevado más de 30 segundos la creación de las bases, además si ha ido bien las de memoria ya no se vuelven a crear.
Hay dos archivos para recopilación de datos:
- datos-comunes; aquí he puesto los datos que son comunes haga los scripts que haga
- recopmemoria.sh; el porqué del nombre es que lo tecleé mal, pero total no molesta, este es el script que recoge los datos propiamente y los introduce en memoria
WEB1=213................ (como que voy a poner la de verdad ;-)
RECOP1="snmpget -v 1 -c public 213............."
TOTALSWAP=" .1.3.6.1.4.1.2021.4.3.0"
SWAPLIBRE=" .1.3.6.1.4.1.2021.4.4.0"
TOTALRAM=" .1.3.6.1.4.1.2021.4.5.0"
RAMLIBRE=" .1.3.6.1.4.1.2021.4.11.0"
En recopmemoria.sh tenemos un script como este (por supuesto con otros datos):
totalswap1=`$RECOP1$TOTALSWAP |awk '{print $4}'`
swaplibre1=`$RECOP1$SWAPLIBRE |awk '{print $4}'`
swapusado1=`expr $totalswap1 - $swaplibre1`
totalram1=`$RECOP1$TOTALRAM |awk '{print $4}'`
ramlibre1=`$RECOP1$RAMLIBRE |awk '{print $4}'`
ramusado1=`expr $totalram1 - $ramlibre1`
/usr/local/bin/rrdtool update /usr/local/www/data-dist/rrd/db/memoria1.rrd \ N:$totalram1:$ramusado1:$totalswap1:$swapusado1
Bueno y luego simplemente añadí una entrada en el cron que lo ejecute cada
5 minutos
*/5 * * * * /home/scripts/recopmemoria.sh >/dev/null 2>&1
Nota: he tenido que modificar al principo del recopmemoria.sh porque sino me daba un error al no encontrar la fuente del archivo de datos, de modo que he escrito:
#!/usr/local/bin/bash
cd /home/scripts
. datos-comunes
Por qué utilizo rrdtool?, pues por lo mismo que utilizo gentoo, por comodidad, sé que podría tener gráficas con mrtg, pero de hecho no tengo la flexibilidad que tengo con rrdtool, ni podría incluir más de dos fuentes de datos en una gráfica....y porque me da la gana, que yo no obligo a nadie a que ponga las gráficas que uso yo :-)
En siguientes entregas iré completando, a ver si puedo hacer un complemento majo para rrdtool.
Correos con comando "mail"
Una función muy importante de linux muy poco aprovechada es el comando "mail" que sirve para enviar correo. Está muy poco aprovechada por mi, porque casi en exclusiva escribo "mail <>" cuando se pueden poner más cosas si utilizamos las opciones, como por ejemplo:
- -s: ponemos asunto
- -c: copiamos a alguien
- -b: copia oculta
echo "Vamos mañana" | mail -c pepe@dominio.com -b marta@dominio.com -s "fiesta" carlos@dominio.comEl tratamiento de archivos será lo próximo. Tenía que escribir esto para que no se me olvidara, como fuente shelldorado, pero lo de los archivos si que va a ser tomado en total de la página.
En algunas versiones de sistemas operativos no está disponible
el programa mail porque tienen la versión extendida "mailx",
o porque el comando no es "mail" sino "Mail" con mayúscula.
Suscribirse a:
Comentarios (Atom)